Synteettinen terveysdata palvelee lääketieteellistä tutkimusyhteistyötä ja uusien terveysteknologioiden kehittämistä
Turun yliopiston ja Turun AMK:n tutkijat ovat kehittäneet tekoälyyn pohjautuvia menetelmiä tuottaa synteettistä terveysdataa. Synteettinen terveysdata jäljittelee todellista dataa niin että sitä voidaan hyödyntää lääketieteen tutkimusyhteistyössä sekä diagnostiikan menetelmien ja terveysalan sovellusten kehitystyössä tietosuojaa kunnioittaen.
Lääketieteen ja terveysteknologian sovellukset ja laitekehitys sekä diagnostiikan menetelmien kehitystyö edellyttävät luotettavia tietoaineistoja testaukseen ja menetelmien validointiin. Todellisten terveystietojen käyttö kuitenkin vaarantaisi terveydenhuollon asiakkaiden tietosuojan.
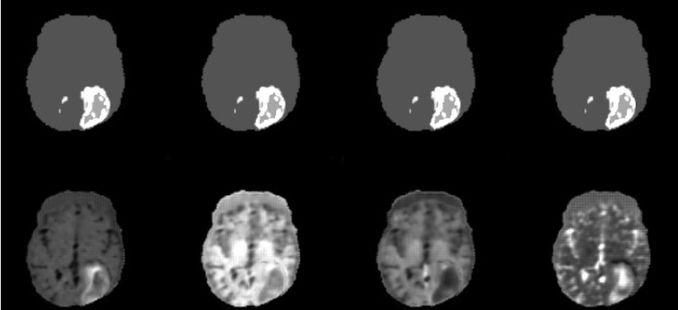
Synteettisestä datasta henkilötiedot on häivytetty tilastollisen kohinan avulla. Kun aineistossa on sopivasti epätarkkuutta, siitä ei voi luotettavasti päätellä yksilön ominaisuuksia. Sen sijaan yleisten havaintojen tulisi säilyä kirkkaina kohinasta huolimatta ja vastata todellisissa verrokkiaineistoissa esiintyviä ilmiöitä. Synteettinen, anonyymi data voi olla muodoltaan tekstiä, mittaussarjoja tai kuvaa, kuten kuvantamisaineistoa.
Synteettisen terveysdatan käyttökohteita ovat esimerkiksi elimistön kuvantamisdatan käsittelyyn kehitetyt sovellukset, joiden testaus ja validointi edellyttävät luotettavia tietoaineistoja. Datan avulla voidaan myös kehittää ennustemalleja tarttuvien tautien leviämisestä sekä simuloida terveyspoliittisten toimien vaikutuksia.
Turun yliopiston ja Turun ammattikorkeakoulun tutkijat ovat kehittäneet tekoälyyn pohjautuvia menetelmiä terveysdatan käsittelyyn yksityisyyden suojan turvaavalla tavalla. Innovaatioista kaksi on edennyt patenttihakemusvaiheeseen.
Synteettisen datan käyttöä on harkittava tapauskohtaisesti
Vaikka synteettisen datan käyttöön sisältyy paljon mahdollisuuksia ja tekoälyalgoritmien kehittyessä datan luotettavuus paranee, on sen käyttöön vielä suhtauduttava varovaisuudella. Synteettisen datan käyttö edellyttää aina tapauskohtaista harkintaa ja korkean riskin tapauksissa, kuten lääketieteellisessä diagnostiikassa, päätösten tulisi aina pohjautua aitoon terveysdataan keinotekoisen sijaan.
– Synteettisellä datalla voidaan saada myös valheellisen tarkkoja tai merkitseviä tuloksia. Eli asiat näyttävät analyytikon silmin selkeämmiltä kuin ne todellisuudessa ovatkaan. Tämän perusteella analyysin tuloksia voidaan pitää ansaittua luotettavimpina ja sen perusteella tehdä vääriä johtopäätöksiä, varoittelee data-analytiikan professori Tapio Pahikkala Turun yliopistosta.
– Synteettisen terveysdatan tuottaminen on tasapainoilua luotettavuuden ja yksityisyydensuojan välillä. Ollakseen käyttökelpoista tietoaineistojen pitäisi olla todentuntuisia mutta tietosuojasta ja anonymiteetistä pitää myös varmistua, toteaa yliopettaja, Turun AMK:n Terveysteknologia-tutkimusryhmän vetäjä Elina Kontio.
Tekoälymenetelmiä synteettisen terveysdatan tuottamiseen on kehitetty PRIVASA (Privacy Preserving AI for Synthetic and Anonymous Health Data) -hankkeessa. Hankkeen tavoitteena on nopeuttaa yritysten tuotekehitystä tuottamalla anonyymia, yksilötasoista terveysdataa. PRIVASA-hankkeessa kehitetyt tekoälyalgoritmit muuntavat henkilötietoja sisältävät aineistot muotoon, jossa niiden käyttö lääke- ja terveystieteelliseen tutkimukseen, testaukseen ja validointiin on mahdollista, tietosuojaa kunnioittaen.
Business Finlandin rahoittamassa PRIVASA-hankkeessa ovat mukana Turun yliopisto, Turun ammattikorkeakoulu ja Teknologian tutkimuskeskus VTT sekä yrityksistä Bayer, BCB Medical, BC Platforms, Fujitsu Finland, MVision, Perkin Elmer, Polar Electro ja Yield Systems. Hankkeeseen ovat tuoneet asiantuntemustaan myös Auria Tietopalvelut, THL ja Findata.
Terveysteknologian tutkimusryhmä
Lisätiedot ajankohtaisesta
